






Imagine you are running your application, and it works just fine. But after a while, your pages slow down, database queries keep increasing, and users start abandoning your app. You try everything; scale your servers, optimize your queries, and still the problem persists.
This is where most developers suggest caching. However, not all caching is the same. If you place random cache here and there, it won’t work. That is why Java Caching System offers a structured, thoughtful, and layered approach to managing data in memory. This keeps your application fast, reliable, and scalable. This is especially important as application performance optimization has become a core concern in modern backend development.
What Is Java Caching System (JCS)?
Java Caching System or JCS refers to a distributed caching solution that is especially built for Java applications. If we talk about its origin, then it was first developed as part of the Apache Turbine project. Later, it emerged as a standalone Apache Commons component known as Apache JCS.
So, why was it designed in the first place? It was designed for the purpose of storing data in memory that is accessed frequently. There is no need to go through the entire database or any external resource to look for the same data again.
JCS is different because it does not store cache data in one place. It supports multiple storage regions. It means you can club related data together and control how long each group can stay active. You can also decide what happens after the memory gets full. With this, developers can control caching behavior instead of being forced to work with one-size-fits-all solution.
How Java Caching System (JCS) Works
JCS sits between your application and your data source. When your application asks for any data, the Java caching system checks to find out whether it already has it stored. It yes, then it returns the cached version immediately. If it does not, it fetches the data from the original source, keeps a copy, and then returns it.
This architecture aligns well with software development trends pushing toward distributed, memory-efficient systems. This process follows three simple steps:
- Cache Lookup: The application requests data. JCS checks its memory regions first.
- Cache Hit or Miss: If the data is found (a hit), it is returned instantly. If not (a miss), JCS fetches it from the source.
- Cache Population: The freshly fetched data is stored in the cache for future requests.
JCS organizes its caching into regions, which are named segments of the cache. Each region can have its own configuration, size limits, expiration time, and auxiliary cache settings. This means you can cache user sessions differently from product catalog data, all within the same system.
Underneath this, JCS uses auxiliary caches such as secondary storage layers like disk-based caches that kick in when memory is limited. So even if something gets pushed out of memory, it does not disappear entirely. It moves to disk and can still be retrieved faster than going back to the database.
Main Types of Caches in JCS
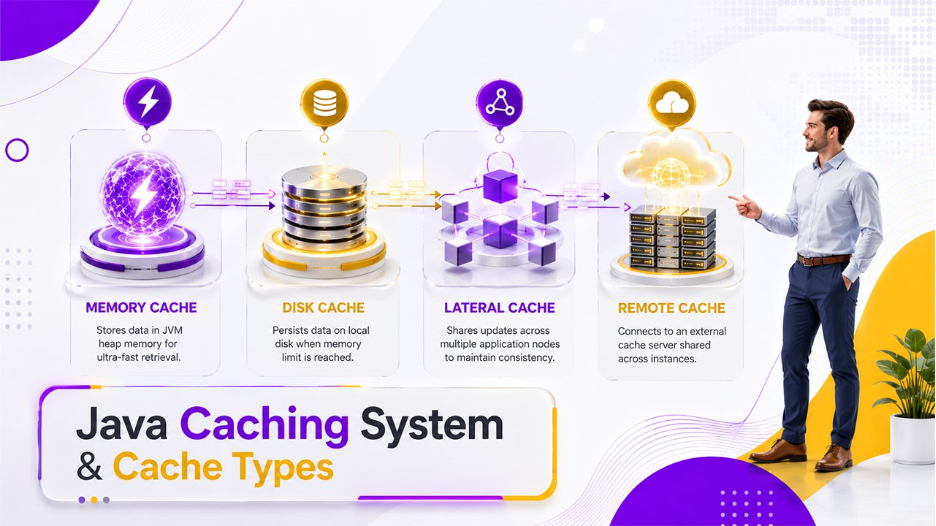
Let’s first understand the different types of caches that exist in a Java Caching System. This helps because the right technique often depends on the right cache type.
Memory Cache
It is the fastest layer that is available. You can retrieve data instantly because it stores data directly in the JVM’s heap memory. It works best for small and frequently accessed data like user sessions or configuration values. However, it has its downside. Once the application shuts down, the data is gone.
Disk Cache
This works as a secondary layer. It intervenes when the memory cache reaches its limit. JCS does not drop the data entirely; instead, it writes it to the local file system. It is slower than memory. However, it is much faster than going back to the original database. Additionally, it survives memory pressure without data loss.
Lateral Cache
It is built for multi-node environments. When your application runs across multiple servers, the lateral cache allows each node to share cache updates with the others. If one node updates a value, the rest are notified so they stay consistent. This way no node serves stale or outdated data.
Remote Cache
It connects to a dedicated external cache server that all application instances share. This is considered the most scalable type. It is commonly used in microservices architectures where consistency across services matters as much as speed.
Here’s a quick comparison of the different cache types in JCS, including where they store data, their ideal use cases, and persistence support.
Your choice of cache type often depends on your infrastructure whether you are on dedicated servers or cloud environments significantly shapes that decision.
| Cache Type | Storage Location | Best Used For | Persistence |
| Memory Cache | JVM Heap Memory | Frequently accessed, small data | No |
| Disk Cache | Local File System | Overflow from memory, larger data | Yes |
| Lateral Cache | Other JVM instances | Distributed/multi-node apps | No |
| Remote Cache | Remote cache servers | Shared caching across services | Depends on setup |
Top Features of Java Caching System (JCS)
JCS comes with a lot of useful features which makes it more than just a simple key-value store:
Region-based Configuration: It allows each cache region to be configured independently with its own size, expiry, and behavior.
Group-Based Cache Management: With this, you can tag related items together, dissolve them, or retrieve them as a group. This is really helpful in real-world applications.
LRU (Least Recently Used) Eviction: When your memory fills up, the JCS removes data that hasn’t been used recently. It only keeps the most relevant data in memory.
Disk Overflow Support: Additional data that doesn’t fit in the memory gets written to disk automatically without crashing or dropping data.
Pluggable Architecture: You can replace or extend individual components such as memory managers, disk caches, and serializers without having to rewrite everything from scratch.
Thread Safety: JCS is built to handle concurrent access safely. This makes it reliable in multi-threaded Java applications.
Time-to-Live (TTL) Support: You can set how long cached data should remain valid before it expires automatically.
Popular Java Caching Techniques and Their Implementations
Understanding which technique to reach for is what separates a thoughtful developer from someone who just drops a cache in and hopes for the best.
1. Time-to-Live (TTL)
TTL is one of the most fundamental ideas in caching. Every cache entry gets a lifespan. Once that lifespan expires, the entry is automatically removed, and the next request fetches fresh data from the source. It prevents your cache from holding onto outdated information indefinitely.
When to use:
- Short TTL for data that changes often, like live prices or user activity feeds, and a
- Long TTL for stable data like user roles or app configuration settings.
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import java.util.concurrent.TimeUnit;
public class CaffeineTTLExample {
public static void main(String[] args) {
Cache<String, String> cache = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.SECONDS) // TTL = 10 seconds
.maximumSize(100)
.build();
cache.put("user:123", "John Doe");
System.out.println("Cached Value: " + cache.getIfPresent("user:123"));
// After 10 seconds, this entry automatically expires
}
}The expireAfterWrite(10, TimeUnit.SECONDS) line is where the TTL is set. Ten seconds after the entry is written, it silently disappears from the cache. The next request will find nothing and go back to the data source, bringing back fresh data and re-populating the cache.
2. Cache Invalidation
TTL handles expiry over time, but what happens when data changes right now? That is where cache invalidation comes in. Invalidation is the process of explicitly removing a stale cache entry the moment the underlying data changes, so the cache never has a chance to serve outdated information.
There are three ways to approach this:
- Write Invalidation: Remove the cache entry as soon as a database write happens.
- Time-based Invalidation: Let TTL do the work automatically.
- Explicit Invalidation: Manually remove the entry whenever your application logic determines it is no longer valid.
Once TTL expires or cache is invalidated, the entries are gone, pairing this with a warmup cache request strategy ensures your cache is never cold when users arrive.
The example below uses Guava Cache to demonstrate explicit invalidation:
import com.google.common.cache.CacheBuilder;
import com.google.common.cache.Cache;
public class GuavaCacheInvalidationExample {
public static void main(String[] args) {
Cache<String, String> cache = CacheBuilder.newBuilder()
.maximumSize(100)
.build();
cache.put("product:101", "Laptop");
System.out.println("Before Invalidation: " + cache.getIfPresent("product:101"));
cache.invalidate("product:101"); // Explicitly remove the entry
System.out.println("After Invalidation: " + cache.getIfPresent("product:101")); // null
}
}Once invalidate() is called on the key, the entry is gone. The next call to getIfPresent() returns null, which signals the application to reload the data fresh. It is simple, precise, and effective for scenarios where you know exactly when data has changed.
3. Publish-Subscribe (Pub/Sub) Caching
When you have multiple instances of an application running at the same time, each with its own local cache, how do you make sure they all stay in sync? If one instance updates a user record and invalidates its own cache, the other instances still have the old data sitting in memory.
This is the problem that Pub/Sub caching solves. One instance publishes a message saying, "this key has changed." Every other instance is subscribed to that channel and receives the message, then invalidates its own copy of that key. The whole system stays consistent without any central coordinator.
Here is an implementation using Redis Pub/Sub with the Jedis library:
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPubSub;
public class RedisPubSubExample {
public static void main(String[] args) {
// Subscriber running in a separate thread
new Thread(() -> {
Jedis subscriberJedis = new Jedis("localhost");
subscriberJedis.subscribe(new CacheInvalidationSubscriber(), "cache-updates");
}).start();
// Publisher sends an invalidation signal
Jedis publisherJedis = new Jedis("localhost");
publisherJedis.publish("cache-updates", "invalidate:user:123");
}
}
class CacheInvalidationSubscriber extends JedisPubSub {
@Override
public void onMessage(String channel, String message) {
System.out.println("Message received: " + message);
if (message.startsWith("invalidate:")) {
String key = message.split(":")[1];
System.out.println("Invalidating cache for: " + key);
// Trigger local cache invalidation here
}
}
} The publisher and subscriber communicate through a shared Redis channel called cache-updates. When the publisher sends "invalidate:user:123", the subscriber picks it up and handles the local invalidation. In a multi-node setup, every node runs a subscriber, so one publish event triggers a cache cleanup across the entire fleet.
4. Write-Through Caching
Write-through caching keeps the cache and database permanently in sync by updating both every time a write operation happens. You never write to the database without also updating the cache, and you never update the cache without also persisting to the database.
This is especially useful when reads are frequent, and a stale cache hit would be costly. The slight trade-off is that write operations take a tiny bit longer since two systems are updated instead of one, but the consistency payoff is almost always worth it.
The cleanest way to implement write-through in Java is using Spring Boot with Redis and its caching annotations:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.cache.annotation.CachePut;
import org.springframework.stereotype.Service;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
@Cacheable(value = "users", key = "#id")
public User getUserById(Long id) {
return userRepository.findById(id)
.orElseThrow(() -> new RuntimeException("User not found"));
}
@CachePut(value = "users", key = "#user.id")
public User updateUser(User user) {
userRepository.save(user); // Saves to the database
return user; // Also updates the cache automatically
}
} @Cacheable handles reads. It checks the cache first and only hits the database on a miss. @CachePut handles writes. It always updates the cache alongside the database, ensuring they never drift apart. The elegance here is that Spring handles most of this invisibly through annotations, keeping your business logic clean. For teams using MySQL IDE tools to manage their databases, write-through caching is a practical way to reduce repetitive query load without sacrificing data consistency.
5. Distributed Locking
Even with the best caching strategy in place, distributed systems have one stubborn problem which is race conditions. When multiple instances of your application try to update the same cache entry at the same moment, you can end up with corrupted or inconsistent data. Distributed locking solves this by ensuring only one instance can touch a shared resource at a time.
Here is how to implement it using Redis with the Redisson library:
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import java.util.concurrent.TimeUnit;
public class DistributedLockExample {
public static void main(String[] args) throws InterruptedException {
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
RedissonClient redisson = Redisson.create(config);
RLock lock = redisson.getLock("cacheLock");
if (lock.tryLock(5, 10, TimeUnit.SECONDS)) {
try {
System.out.println("Lock acquired. Updating cache safely...");
// Safe cache update logic here
} finally {
lock.unlock();
}
} else {
System.out.println("Could not acquire lock. Another instance is updating.");
}
}
} The tryLock(5, 10, TimeUnit.SECONDS) call tries to acquire the lock within 5 seconds and holds it for a maximum of 10 seconds. Only one instance succeeds. The others wait or back off gracefully. This prevents simultaneous conflicting writes and keeps your cache data reliable.
6. Redlock Algorithm
Distributed locking on a single Redis node works well until that node goes down. The Redlock algorithm, developed by the Redis team, solves exactly this problem. Instead of relying on one Redis node, Redlock acquires locks on multiple independent Redis nodes simultaneously. If the majority of nodes grant the lock within a defined time window, the lock is considered successfully acquired. A single node failure cannot break the whole mechanism.
Here is how Redlock looks using Redisson's built-in multi-lock support:
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.redisson.api.RedissonMultiLock;
public class RedlockExample {
public static void main(String[] args) {
RedissonClient redisson = Redisson.create(); // Configure for multi-node Redis
RLock lock1 = redisson.getLock("node1Lock");
RLock lock2 = redisson.getLock("node2Lock");
RLock lock3 = redisson.getLock("node3Lock");
RedissonMultiLock redlock = new RedissonMultiLock(lock1, lock2, lock3);
if (redlock.tryLock()) {
try {
System.out.println("Redlock acquired. Safe to perform critical operations.");
// Critical cache update logic
} finally {
redlock.unlock();
}
}
}
} Three separate locks are created across three Redis nodes. RedissonMultiLock bundles them together and tries to acquire all three. If at least two of the three succeed, the lock is granted. This majority-based approach makes your caching layer resilient to node failures, which is a real concern in production environments.
Conclusion
A Java Caching System (JCS) is a design decision that you must make early on, understand thoroughly, and implement with purpose. JCS gives you genuine control over your application’s performance. It organizes data into regions, supports multiple cache types, and puts powerful techniques in your hand.
Start simple with cache-aside, build up to write-through for write-heavy systems, and use TTL and group caching to keep your data fresh and manageable. Performance is not always about doing more. Sometimes, it is about being smart enough to not repeat yourself, and that is exactly what a well-implemented java caching system does.

