






Businesses in 2026 face a stubborn reality. Manual workflows throttle growth. Content creation chokes marketing velocity. Support teams drown in repetitive tickets, and decision-makers sift through data sludge. The bottleneck is human bandwidth. Many companies now choose generative ai development services to build smarter automation workflows because generic SaaS tools can't bridge this gap.
GenAI has shifted from an experimental toy to essential infrastructure. This is about engineering systems that work at your scale, with your data, within your guardrails. Let's talk about how that actually gets built.
What Generative AI Means for Modern Business Teams
Forget the hype. Think interfaces. Traditional automation follows rigid, pre-defined rules. It breaks when tasks require understanding language, context, or nuance. Generative AI, built on Large Language Models (LLMs), is different. It's a flexible reasoning engine trained on patterns. You give it a prompt, such as a question or a task, and it generates a novel, context-aware output.
This turns an LLM into a new kind of interface for your proprietary data and processes. Your team is not coding every single response. They are directing a system that can interpret and create. That's the fundamental shift driving custom generative AI development services. It’s less about artificial intelligence and more about applied language engineering.
Where Generative AI Delivers Real Business Value
GenAI isn't a magic wand for every problem. It delivers ROI where tasks are repetitive, language-centric, and knowledge-bound. Think of domains drowning in text, unstructured data, or routine decision patterns. The value proposition is stark: augment human effort, accelerate throughput, and unlock insights buried in documents and databases.
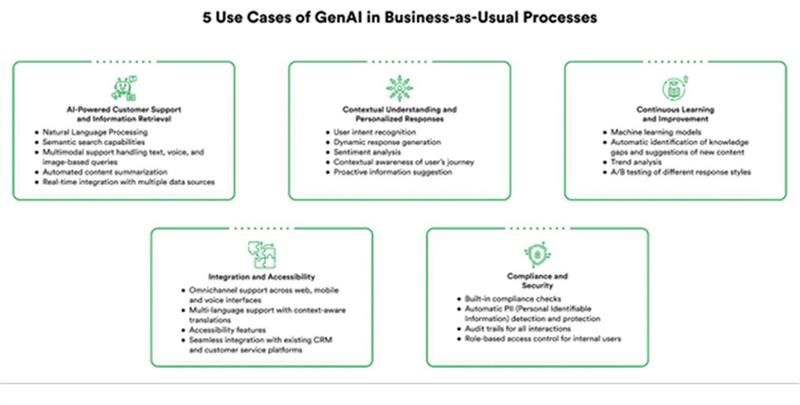
Primary use cases demonstrating measurable impact include:
- AI automation for customer support;
- Content creation and review workflows;
- Internal knowledge search using RAG;
- AI in CRM for sales and proposal generation
- Decision support and analytics summarization.
The common thread is the transformation of unstructured information into structured, actionable output.
The effect is not just qualitative. It is quantifiable through reduced handle times, faster content cycles, and improved decision latency.
Example of a Real Generative AI Implementation
Consider a tangible case. A client in the logistics sector struggled with a bloated, slow-moving support desk. Agents spent over 70% of their time retrieving shipping rules, tariff codes, and policy exceptions from a fragmented wiki and PDF repository. Email response times ballooned.
An internal knowledge assistant was architected using a RAG (Retrieval-Augmented Generation) pipeline. The system indexed all internal documents into a vector database. When an agent asked a question, it retrieved the relevant snippets and an LLM synthesized a concise, sourced answer.
The outcome was mechanical, not magical. First-contact resolution rate jumped by 40% because agents had instant, accurate information. Average handle time dropped by 35%. The system didn't replace agents; it made them dramatically more efficient. The key was framing the problem correctly: not as a chatbot replacement, but as a latency reduction tool for human experts.
Typical GenAI Solution Architecture
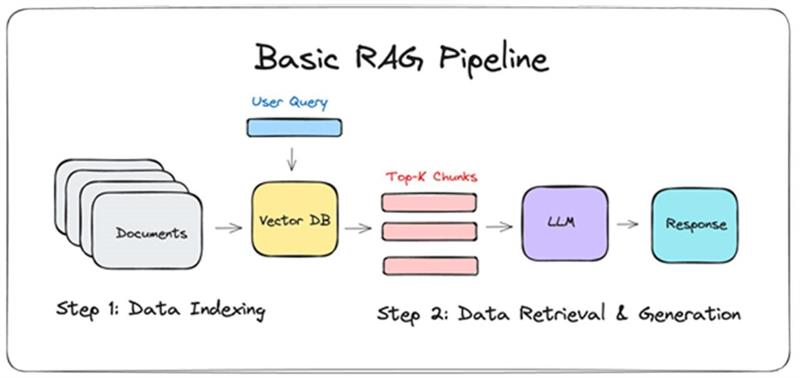
Building a production system is more than just API calls to ChatGPT. You need a resilient pipeline. A standard architecture for a GenAI application involves several linked components. It starts with the user prompt or query. This input often triggers a retrieval step, especially for knowledge-intensive tasks.
Here, technologies like vector databases (Pinecone, Weaviate, FAISS) search your internal data to find relevant context. This context is then fed, alongside the original prompt, to the core LLM. The model generates the response. Finally, output guardrails and filters evaluate the response for safety, accuracy, and alignment before it reaches the user.
The critical engineering choice is between fine-tuning a base model and using RAG. Fine-tuning permanently alters the model's weights on your specific data, good for mastering a consistent style or domain.
RAG keeps the base model static but augments it with real-time data retrieval, ideal for dynamic, factual knowledge. Most enterprise implementations start with RAG. It's faster to implement, easier to update, and mitigates hallucination risks by grounding answers in retrieved documents.
Security, Privacy, and Data Risks
Ignoring this section is professional negligence. Generative AI introduces novel attack surfaces and compliance nightmares. Sending proprietary data to a third-party model API can constitute a permanent data leak, as that data may become part of the model's training corpus.
Hallucinations can produce confident and plausible outputs that are entirely incorrect, which poses severe risks in legal, medical, or financial contexts. Bias in training data propagates to outputs, creating brand and legal exposure.
Critical non-negotiable risks to model include:
- Data leakage risks;
- Hallucinations in critical workflows;
- Bias and output inconsistency;
- Regulatory and compliance exposure.
In real deployments, safety comes down to basic discipline. Outputs that affect users or decisions should be reviewed by humans. Models need to be tested on realistic cases before launch, not just happy paths. After release, teams have to watch how the system behaves and catch issues early.
Most teams rely on existing guidance to structure this work. The NIST AI Risk Management Framework is often used as a reference for risk and accountability. OpenAI deployment guidelines also stress data isolation, controlled access, and ongoing evaluation once systems are live. The goal is simple: reduce avoidable risk without slowing the business to a halt.
How to Choose a Generative AI Development Partner
Choosing a vendor matters more than most teams expect. A demo built on public APIs is easy. A production system tied into your data, security model, and internal tools is not.
When companies invest in custom generative ai development services, they are committing to long-term ownership. That means reliability, access control, and maintenance matter more than clever prompts. The partner needs to know how to build and support systems that actually run inside a business.
Key differentiators in a competent generative ai development service provider:
- Experience with LLM application development;
- Understanding of fine-tuning vs RAG trade-offs;
- Security and compliance-first approach;
- Ability to integrate with enterprise systems;
- Clear evaluation and deployment process.
This checklist directly connects to your time-to-value and risk reduction. A partner that talks endlessly about model parameters but has no clear plan for data governance or production monitoring is selling you a science project, not a business solution.
Conclusion
By 2026, generative AI is no longer experimental. It’s a practical tool for automating specific, language-heavy tasks across content, support, and analysis. These systems don’t think or reason. They follow statistical patterns inside carefully designed pipelines.
Teams that see results focus on clear use cases, stable architectures, and basic security from day one. The advantage comes from disciplined execution, not flashy demos or inflated promises.

